



/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
Todo清單v2.0.0官方版京東自動搶券v1.50免費版Everything官方版v1.4.1.998最新版LOL英雄聯盟角色變大工具v1.0 綠色防封版美圖秀秀64位最新版v6.4.2.0 官方版福昕pdf編輯器去水印綠色版(圖像處理) v9.2 最新版微軟必應詞典官方版(翻譯軟件) v3.5.4.1 綠色版搜狗輸入法電腦最新版(輸入法) v9.3.0.2941 官方版網易音樂(音樂) v2.5.5.197810 電腦版 WPS Office 2019 電腦版(WPS Office ) 11.1.0.8919全能完整版還在尋找免費的OCR文字識別軟件,小編這裏向你推薦abbyy finereader12簡體中文版這款附序列號的軟件來試一試吧,泰比abbyy finereader12破解版應吧軟件中所有的收費功能全部破解了,現在在免費就可以使用,abbyy finereader12簡體中文版安裝說明下麵也有介紹,另外軟件要管理員權限才可運行!

ABBYY FineReader12是一款功能強大的OCR文字識別軟件,它可以從圖片上識別文件或表格,識別率非常高,對於英文的識別可以說是高達99%,而漢字的識別也在99%。與同類軟件相比,具有識別速度快、支持語言最多等特點,識別後能夠自動檢查並調整識別結果,軟件的操作界麵非常直觀,使用起來也比較上手。其識別速度與電腦的配置有直接的關係,電腦配置越高識別的速度也就越快。另外它還是一款掃描儀軟件,能夠將文件掃描到PDF,將整個頁麵圖像保存為一個圖片,並將已識別的文本置於其下,使用該選項創建可進行全文搜索的文檔,且該文檔看上去幾乎與原始文檔相同。
將圖像文件轉換至PDF文檔,掃描並保存為圖像,保存頁麵的精確圖像,用戶幾乎很難區分這類PDF文檔和原始文檔的差別,但不能對其進行搜索,另外也可以掃描為HTML,掃描到EPUB為電子書設備創建書籍。
安裝方式包括典型安裝及自定義安裝,可以選擇自由選擇安裝的組件。
ABBYY Screenshot Reader可以捕捉屏幕中的矩形區域,並將它轉換為文本、表格或圖像。

輸入格式:
PDF、PDF/A、TIFF、JPEG、JPEG 2000、JBIG2、PNG、BMP、PCX、GIF、DjVu、XPS(需要Microsoft .NET Framework 4.0)、DOC(X)、XLS(X)、PPT(X)、VSD(X)、HTML、RTF、TXT、ODT、ODS、ODP。
支持語言:
ABBYY FineReader多語言專業版
識別語言:192種識別語言(包括阿拉伯語,中/日/韓,希伯來語等),其中,48種識別語言帶字典支持
用戶界麵語言:24 種用戶界麵語言
圖像存儲格式:
TIFF、JPEG、JPEG 2000、JBIG2、PNG、BMP、PCX、DjVu。
文件存儲格式:
PDF(可搜索、僅圖像、文本和圖像),包括PDF/A (1a、1b、2a、2b、2u、3a、3b、3u)、DOC(X)、XLS(X)、PPT、HTML、RTF、TXT、CSV、ODT、EPUB、FB2。'
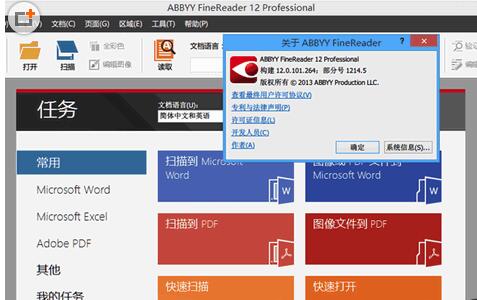
解壓後打開SETUP文件夾內的AutoRun.exe,選擇安裝ABBYY FineReader 12選項,然後選擇軟件語言。
安裝之後不要立即運行ABBYY FineReader 12,以管理員模式運行“Del_Lic_Serv.bat”來停止軟件的後台服務。
將CK文件夾內的所有文件都複製到C:\Program Files\ABBYY FineReader 12\目錄下麵,覆蓋原來的文件即是注冊版。
 飛揚動力雲端版(基於雲技術) v1.0 最新版其它行業
/ 767K
飛揚動力雲端版(基於雲技術) v1.0 最新版其它行業
/ 767K
 香溢購煙草網上訂貨平台官方版(煙草訂煙) 免費版其它行業
/ 4M
香溢購煙草網上訂貨平台官方版(煙草訂煙) 免費版其它行業
/ 4M
 建設銀行二代網銀盾驅動程序(UKey驅動) v3.0.7.0 最新版其它行業
/ 21M
建設銀行二代網銀盾驅動程序(UKey驅動) v3.0.7.0 最新版其它行業
/ 21M
 Mindjet MindManager2018注冊機(含注冊碼密匙) 免費版其它行業
/ 190M
Mindjet MindManager2018注冊機(含注冊碼密匙) 免費版其它行業
/ 190M
 好分數雲校閱卷客戶端官方版(電腦閱卷) v1.5.16 免費電腦版其它行業
/ 192K
好分數雲校閱卷客戶端官方版(電腦閱卷) v1.5.16 免費電腦版其它行業
/ 192K
 JMatPro10.0中文版(附使用教程) 免費版其它行業
/ 82M
JMatPro10.0中文版(附使用教程) 免費版其它行業
/ 82M
 KEPServerEX V6完美版v6.5.829其它行業
/ 407M
KEPServerEX V6完美版v6.5.829其它行業
/ 407M
 浙江省自然人稅收管理係統扣繳客戶端官方版(個人所得稅代扣代繳客戶端) v3.0.008 最新版其它行業
/ 138M
浙江省自然人稅收管理係統扣繳客戶端官方版(個人所得稅代扣代繳客戶端) v3.0.008 最新版其它行業
/ 138M
 機機樂5g軟件2019免費版(收銀總後台管理) 最新版其它行業
/ 39M
機機樂5g軟件2019免費版(收銀總後台管理) 最新版其它行業
/ 39M
 漳州煙草網上訂貨係統(漳州煙草訂貨平台) 免費版其它行業
/ 1M
飛揚動力雲端版(基於雲技術) v1.0 最新版其它行業
/ 767K
香溢購煙草網上訂貨平台官方版(煙草訂煙) 免費版其它行業
/ 4M
建設銀行二代網銀盾驅動程序(UKey驅動) v3.0.7.0 最新版其它行業
/ 21M
Mindjet MindManager2018注冊機(含注冊碼密匙) 免費版其它行業
/ 190M
好分數雲校閱卷客戶端官方版(電腦閱卷) v1.5.16 免費電腦版其它行業
/ 192K
JMatPro10.0中文版(附使用教程) 免費版其它行業
/ 82M
KEPServerEX V6完美版v6.5.829其它行業
/ 407M
浙江省自然人稅收管理係統扣繳客戶端官方版(個人所得稅代扣代繳客戶端) v3.0.008 最新版其它行業
/ 138M
機機樂5g軟件2019免費版(收銀總後台管理) 最新版其它行業
/ 39M
漳州煙草網上訂貨係統(漳州煙草訂貨平台) 免費版其它行業
/ 1M
飛揚動力雲端版(基於雲技術) v1.0 最新版其它行業
香溢購煙草網上訂貨平台官方版(煙草訂煙) 免費版其它行業
建設銀行二代網銀盾驅動程序(UKey驅動) v3.0.7.0 最新版其它行業
Mindjet MindManager2018注冊機(含注冊碼密匙) 免費版其它行業
好分數雲校閱卷客戶端官方版(電腦閱卷) v1.5.16 免費電腦版其它行業
JMatPro10.0中文版(附使用教程) 免費版其它行業
KEPServerEX V6完美版v6.5.829其它行業
浙江省自然人稅收管理係統扣繳客戶端官方版(個人所得稅代扣代繳客戶端) v3.0.008 最新版其它行業
機機樂5g軟件2019免費版(收銀總後台管理) 最新版其它行業
漳州煙草網上訂貨係統(漳州煙草訂貨平台) 免費版其它行業
/ 1M
飛揚動力雲端版(基於雲技術) v1.0 最新版其它行業
/ 767K
香溢購煙草網上訂貨平台官方版(煙草訂煙) 免費版其它行業
/ 4M
建設銀行二代網銀盾驅動程序(UKey驅動) v3.0.7.0 最新版其它行業
/ 21M
Mindjet MindManager2018注冊機(含注冊碼密匙) 免費版其它行業
/ 190M
好分數雲校閱卷客戶端官方版(電腦閱卷) v1.5.16 免費電腦版其它行業
/ 192K
JMatPro10.0中文版(附使用教程) 免費版其它行業
/ 82M
KEPServerEX V6完美版v6.5.829其它行業
/ 407M
浙江省自然人稅收管理係統扣繳客戶端官方版(個人所得稅代扣代繳客戶端) v3.0.008 最新版其它行業
/ 138M
機機樂5g軟件2019免費版(收銀總後台管理) 最新版其它行業
/ 39M
漳州煙草網上訂貨係統(漳州煙草訂貨平台) 免費版其它行業
/ 1M
飛揚動力雲端版(基於雲技術) v1.0 最新版其它行業
香溢購煙草網上訂貨平台官方版(煙草訂煙) 免費版其它行業
建設銀行二代網銀盾驅動程序(UKey驅動) v3.0.7.0 最新版其它行業
Mindjet MindManager2018注冊機(含注冊碼密匙) 免費版其它行業
好分數雲校閱卷客戶端官方版(電腦閱卷) v1.5.16 免費電腦版其它行業
JMatPro10.0中文版(附使用教程) 免費版其它行業
KEPServerEX V6完美版v6.5.829其它行業
浙江省自然人稅收管理係統扣繳客戶端官方版(個人所得稅代扣代繳客戶端) v3.0.008 最新版其它行業
機機樂5g軟件2019免費版(收銀總後台管理) 最新版其它行業





