



/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
Todo清單v2.0.0官方版京東自動搶券v1.50免費版Everything官方版v1.4.1.998最新版LOL英雄聯盟角色變大工具v1.0 綠色防封版美圖秀秀64位最新版v6.4.2.0 官方版福昕pdf編輯器去水印綠色版(圖像處理) v9.2 最新版微軟必應詞典官方版(翻譯軟件) v3.5.4.1 綠色版搜狗輸入法電腦最新版(輸入法) v9.3.0.2941 官方版網易音樂(音樂) v2.5.5.197810 電腦版 WPS Office 2019 電腦版(WPS Office ) 11.1.0.8919全能完整版kafka能夠針對分布式發布消息進行動作流量數據統計,許多的方法和參數都在kafka權威指南pdf中文版中提供給你!精心製作的kafka電子書教程下載免費即可下載去通過語言簡單精煉清晰來讓kafka權威指南pdf中文版教會你更多kafka相關的技巧和知識,讓你使用kafka更加簡單輕鬆!
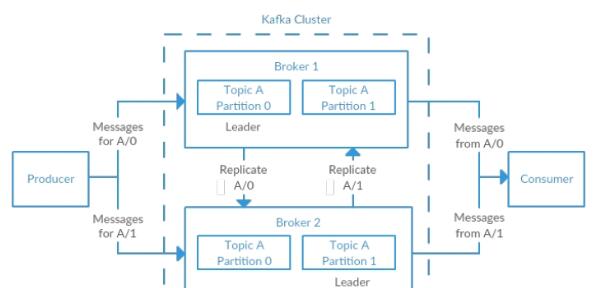
Kafka是一種高吞吐量的分布式發布訂閱消息係統,它可以處理消費者規模的網站中的所有動作流數據。 這種動作(網頁瀏覽,搜索和其他用戶的行動)是在現代網絡上的許多社會功能的一個關鍵因素。 這些數據通常是由於吞吐量的要求而通過處理日誌和日誌聚合來解決。 對於像Hadoop的一樣的日誌數據和離線分析係統,但又要求實時處理的限製,這是一個可行的解決方案。Kafka的目的是通過Hadoop的並行加載機製來統一線上和離線的消息處理,也是為了通過集群來提供實時的消費。
Partition
Partition是物理上的概念,每個Topic包含一個或多個Partition.
Producer
負責發布消息到Kafka broker
Consumer Group
每個Consumer屬於一個特定的Consumer Group(可為每個Consumer指定group name,若不指定group name則屬於默認的group)。
Consumer
消息消費者,向Kafka broker讀取消息的客戶端。
Broker
Kafka集群包含一個或多個服務器,這種服務器被稱為broker
Topic
每條發布到Kafka集群的消息都有一個類別,這個類別被稱為Topic。(物理上不同Topic的消息分開存儲,邏輯上一個Topic的消息雖然保存於一個或多個broker上但用戶隻需指定消息的Topic即可生產或消費數據而不必關心數據存於何處)
 百度淘寶刷下拉快速優化排名神器(SEO優化工具) v6.7 特別版網絡輔助
/ 4.83M
百度淘寶刷下拉快速優化排名神器(SEO優化工具) v6.7 特別版網絡輔助
/ 4.83M
 uninstall tool密鑰最新版網絡輔助
/ 1K
uninstall tool密鑰最新版網絡輔助
/ 1K
 diskgenius離線激活碼永久版網絡輔助
/ 37M
diskgenius離線激活碼永久版網絡輔助
/ 37M
 守望先鋒dva本子完整版(內含視頻) 高清網盤版網絡輔助
/ 1M
守望先鋒dva本子完整版(內含視頻) 高清網盤版網絡輔助
/ 1M
 友邦微信群發軟件(微信推廣工具) v5.7 最新版網絡輔助
/ 27.84M
友邦微信群發軟件(微信推廣工具) v5.7 最新版網絡輔助
/ 27.84M
 網頁自動點擊操作助手電腦版(自動刷網頁點擊數) v19.1.0 免費版網絡輔助
/ 8M
網頁自動點擊操作助手電腦版(自動刷網頁點擊數) v19.1.0 免費版網絡輔助
/ 8M
 CDR注冊機(cdr永久激活代碼) 免費版網絡輔助
/ 323K
CDR注冊機(cdr永久激活代碼) 免費版網絡輔助
/ 323K
 一片雲驗證碼平台(驗證碼接收工具) v6.4 官方最新版網絡輔助
/ 1004K
一片雲驗證碼平台(驗證碼接收工具) v6.4 官方最新版網絡輔助
/ 1004K
 360種子在線編輯器(360種子洗白工具) v1.0.1 綠色免費版網絡輔助
/ 1M
360種子在線編輯器(360種子洗白工具) v1.0.1 綠色免費版網絡輔助
/ 1M
 奧維互動地圖vip賬號分享工具(奧維地圖vip賬號大全) v2017 免費版網絡輔助
/ 28M
百度淘寶刷下拉快速優化排名神器(SEO優化工具) v6.7 特別版網絡輔助
/ 4.83M
uninstall tool密鑰最新版網絡輔助
/ 1K
奧維互動地圖vip賬號分享工具(奧維地圖vip賬號大全) v2017 免費版網絡輔助
/ 28M
百度淘寶刷下拉快速優化排名神器(SEO優化工具) v6.7 特別版網絡輔助
/ 4.83M
uninstall tool密鑰最新版網絡輔助
/ 1K
 吉吉影音資源BT種子(吉吉影音看片網站) 免費版網絡輔助
/ 397K
diskgenius離線激活碼永久版網絡輔助
/ 37M
守望先鋒dva本子完整版(內含視頻) 高清網盤版網絡輔助
/ 1M
友邦微信群發軟件(微信推廣工具) v5.7 最新版網絡輔助
/ 27.84M
網頁自動點擊操作助手電腦版(自動刷網頁點擊數) v19.1.0 免費版網絡輔助
/ 8M
CDR注冊機(cdr永久激活代碼) 免費版網絡輔助
/ 323K
360種子在線編輯器(360種子洗白工具) v1.0.1 綠色免費版網絡輔助
/ 1M
一片雲驗證碼平台(驗證碼接收工具) v6.4 官方最新版網絡輔助
/ 1004K
吉吉影音資源BT種子(吉吉影音看片網站) 免費版網絡輔助
/ 397K
diskgenius離線激活碼永久版網絡輔助
/ 37M
守望先鋒dva本子完整版(內含視頻) 高清網盤版網絡輔助
/ 1M
友邦微信群發軟件(微信推廣工具) v5.7 最新版網絡輔助
/ 27.84M
網頁自動點擊操作助手電腦版(自動刷網頁點擊數) v19.1.0 免費版網絡輔助
/ 8M
CDR注冊機(cdr永久激活代碼) 免費版網絡輔助
/ 323K
360種子在線編輯器(360種子洗白工具) v1.0.1 綠色免費版網絡輔助
/ 1M
一片雲驗證碼平台(驗證碼接收工具) v6.4 官方最新版網絡輔助
/ 1004K





