



/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
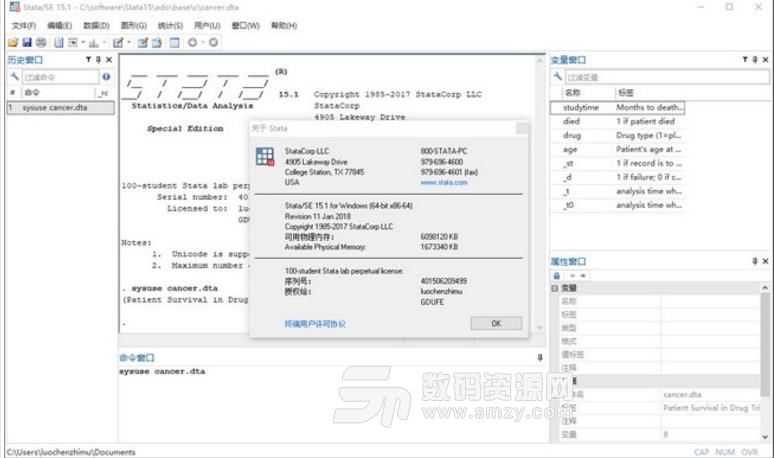
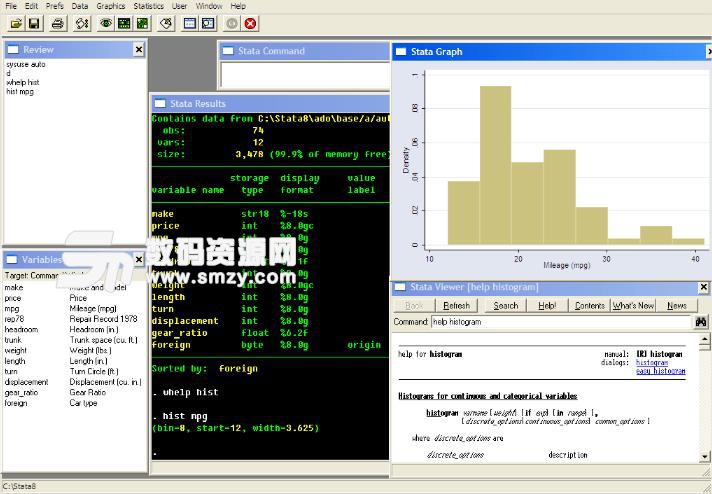
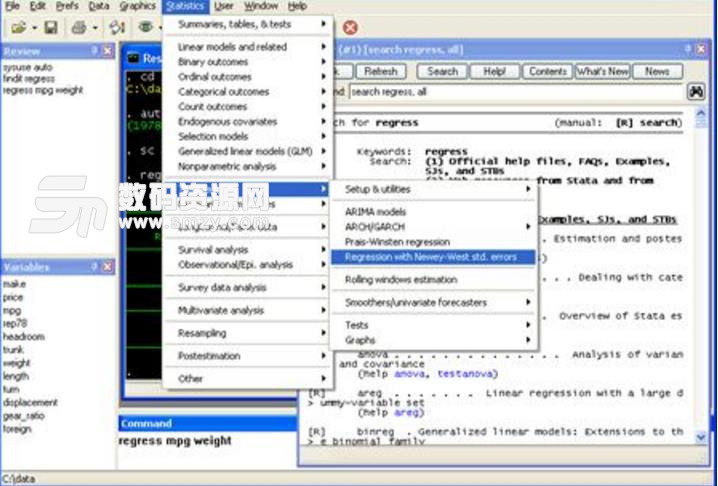
Todo清單v2.0.0官方版京東自動搶券v1.50免費版Everything官方版v1.4.1.998最新版LOL英雄聯盟角色變大工具v1.0 綠色防封版美圖秀秀64位最新版v6.4.2.0 官方版福昕pdf編輯器去水印綠色版(圖像處理) v9.2 最新版微軟必應詞典官方版(翻譯軟件) v3.5.4.1 綠色版搜狗輸入法電腦最新版(輸入法) v9.3.0.2941 官方版網易音樂(音樂) v2.5.5.197810 電腦版 WPS Office 2019 電腦版(WPS Office ) 11.1.0.8919全能完整版Stata15這款統計學軟件有多強大相信大家都有了解,這款Stata15永久授權碼是一個針對這個軟件製作的激活碼軟件,可以幫助您永久激活這款軟件,Stata15序列號能夠幫助您不花一分錢就能夠使用這款軟件的強大功能,如果您想使用Stata15破解版的話就千萬不要錯過這款Stata15永久授權碼!
擴展回歸模型
我們稱之為ERMS 擴展回歸模型。四個新的命令適合
線性回歸分析,
區間回歸包括tobit模型,
概率,
有序概率模型
可任意組合成:
內生變量
非隨機處理任務
內源性(Heckman-style)樣本的選擇
這些新的命令讓人驚喜,因為可以在任何一個方程中加入內生變量,包括處理賦值和概率選擇方程。內生變量並不局限於連續性。它們可以是二進製或序數。不管是外生的還是內生的,它們都可以與其他變量相互作用。它們甚至可以互相作用,形成平方項或立方項!
這些新的ERM命令—eregress,eintreg,eprobit, 和eoprobit注定會流行起來,因為他們解決了研究人員的很多問題。首先, 可能有一個內生變量, 因為許多模型都省略了與模型中的變量相關的變量。其次,數據經常被刪剪,而刪剪不是隨機的。ERM 樣本選擇選項允許您對選擇過程進行建模, 並對其進行調整。或者, 如果您正在使用非隨機處理效應模型, 則可以用 ERM處理分配選項。或者, 可以結合處理分配和選擇選項, 其中一些是由於後續的行為而損失的擬合內生處理分配模型。
潛在類別分析(LCA)
潛在的均值未被觀測。分類也就是分組。潛在類是數據中未觀測到的組。你可能有關於消費者的數據,並且根據消費者對產品的潛在興趣將他們分成三組。但是,在數據中沒有指定每個消費者所屬組的變量。擬合模型後,你可以
使用新的estat lcprob命令估計屬於每一類的消費者比例;
使用新的estat lcprob命令估計每個類中Y1、Y2、Y3、Y4的邊際均值(均值就是示例所示的概率);
使用新estat lcprob命令來評價適合度;
使用現有的predict命令獲取分類成員的預測概率和觀測結果變量的預測值。

貝葉斯前綴指令
新的bayes:前綴命令使你能夠適應比以前版本更廣泛的貝葉斯模型。原來也可以擬合貝葉斯線性回歸, 但是現在可以通過輸入文字就可以:在這個模型中, 為變量 id的每個值添加隨機截距。
新的bayes:前綴命令在許多Stata評估命令之前工作,並提供超過50種可能性的模型。支持的模型包括多級、麵板數據、生存和樣本選擇模型!
新命令支持所有Stata的貝葉斯的功能。你可以從之前的模型參數的分布中選擇,也可以使用之前默認的。當閉合形式解決方案用於Gibbs方法時,可以使用默認的自適應 Metropolis–Hastings 抽樣, 或Gibbs抽樣, 或兩種方法的組合。在bayesmh命令的基礎上可以使用STATA的任何其他功能。可以更改回歸係數的缺省先驗分布,比如,使用prior()選項:
線性動態隨機一般均衡(DSGE)模型
DSGEs是經濟學中的一個時間序列模型。它們是傳統預測模型的替代品。兩者都試圖解釋總的經濟現象, 但 DSGEs 允許對來自經濟理論模型的基礎上做這個。建立在經濟理論基礎上的方程很多。這些方程的關鍵特征是, 未來變量的期望值會影響今天的變量。這是區別 DSGEs 與矢量回歸或狀態空間模型的一個特性。另一個特點是, 從理論推導出來的參數通常可以用這個理論來解釋。
在DSGE模型中有三種變量:
控製變量和方程,如p沒有衝擊,並且是由方程組決定的。
狀態變量 (如 y) 具有隱含的衝擊, 在時間段開始時是預先確定的。
衝擊是驅動係統的隨機錯誤。
在任何情況下, 以上dsge 命令可以定義一個模型並擬合。
如果我們有一個關於 beta 和kappa之間關係的理論, 比如它們是相等的, 我們可以用現有的命令test來測試它。
新的 postestimation命令estat policy和estat transition報告策略和轉換矩陣。如果鍵入
顯示將控製變量作為狀態變量的線性函數。如果有五個控製變量和三個狀態變量, 則每個控件將被報告為三個狀態的線性函數。在上麵的簡單例子中, 預測 p 的線性函數將顯示為現在的 y 函數。
同時,報告轉換矩陣。而策略矩陣將 p 報告為函數y, 而轉換矩陣則報告 y 如何通過時間演變為p。可以使用Stata的現有預測命令來生成預測。可以使用Stata現有的irf命令來繪製脈衝響應函數。
web動態的Markdown文檔
你有沒有聽過Markdown?它是一種創建 html 文檔的流行方式。html 文件是繁瑣的。Markdown簡單直觀,想法很簡單。可以創建一個文件, 其中包含所需的可讀格式的文本, 然後通過它運行一個命令來創建一個HTML文件。
Stata現在支持Markdown, 我們已經添加了標簽 (功能) 到Markdown, 允許包括輸入文件中的Stata命令。你所包含的命令將被運行和顯示, 或者以秘密方式運行, 以及提取輸出的部分供文檔使用。
非線性混合效應模型
非線性混合效應模型也被稱為非線性多級模型和非線性層次模型。可以用兩種方式來考慮這些模型。可以把它們看成包含隨機效應的非線性模型。或者可以把它們看成線性混合效應模型, 其中一些或所有的固定和隨機效應都是非線性的。不管哪種方式, 總的誤差分布假設成Gaussian分布。
這些模型在人口藥代動力學, 生物鑒定和研究生物學和農業成長過程中很流行。比如,采用非線性混合效應模型對機體的藥物吸收、地震強度和植物生長進行了模擬。
新的評估命令被命名為 menl。它實現了 popular-in-practice Lindstrom–Bates 算法, 是基於對固定和隨機效應的非線性均值函數進行線性化。支持最大似然和受限最大似然估計方法。
Menl易於使用。可以直接輸入單個方程。大括號{ },用於將要匹配的參數括起來:
除了標準功能外, postestimation特征還包括對隨機效應及其標準誤差的預測,對模型中定義的感興趣參數的預測, 作為其他模型參數和隨機效應的參數、聚類相關矩陣的整體評估等。
空間自回歸模型(SAR)
Stata適合空間自回歸 (SAR) 模型, 也稱為同步自回歸模型。新的spregress,spivregress, 和spxtregress命令允許因變量的空間滯後、自變量的空間滯後和空間自回歸誤差。空間滯後是時間序列滯後的空間模擬。時間序列滯後近年來成為變量值。空間滯後是附近地區的值。
該模型適用於區域數據, 也稱為區域性數據。觀測結果被稱為空間單位, 可以是國家、州、區、縣、市、郵政編碼或城市街區,或者它們可能根本就不是地理位置。它們可能是社交網絡的節點。空間模型評估直接影響—區域對自身的影響,並估算鄰近地區的間接或溢出效應。
有一個全新的 [SP] 手冊專門介紹Stata的新SAR功能。這些命令被稱為Sp命令。它們可以與以下一起工作:
shapefiles通過 web 獲取你選擇數據,或者
沒有shapefiles 和數據,隻包含位置的坐標,或者
沒有 shapefiles沒有位置會出現社會網絡數據。
區間刪失參數生存時間模型
Stata新的stintreg 命令加入 streg, 用於擬合參數生存模型。stintreg擬合區間刪失數據模型。在區間刪失數據中,故障時間並不確定。眾所周知, 受試者還沒有失敗的時候, 以及後來他們已經失敗的時候。
stintreg擬合指數,Weibull, Gompertz, 對數正態分布、對數邏輯和廣義的gamma生存時間模型。支持比例風險和加速故障時間度量。功能包括
分層估計
靈活的輔助參數建模
robust, cluster–robust, bootstrap,和jackknife的標準誤差
除了基本功能, postestimation功能還包括plots of survivor,, hazard, 和cumulative hazard函數;平均數和中位數時間預測;Cox–Snell and martingale-like殘差值等。
有限混合模型(FMMs)
新的fmm:當數據來自未觀測到的亞群時, 前綴命令擬合模型。它可以與17 個Stata評估命令一起使用。
大多數用戶使用fmm來擬合模型中的參數 (係數、位置、方差、比例等) 在不同亞群之間的變化。在這些模型中,未觀測到的亞群稱為類。比如說你感興趣的擬合模型。每個分類在總人口的比例中,Postestimation 命令可用於 (1) 評估,(2) 報告類內結果變量的邊際均值,預測類成員的概率和預測結果。
混合Logit模型
Stata已經擬合多項Logit模型。Stata15能使它們擬合混合形式, 包括隨機係數。
隨機係數對擬合多項式邏輯模型具有特殊的意義。它們是圍繞Independence of the Irrelevant Alternatives (IIA)假設一種方式。這一假設表明, 如果你選擇步行去工作, 當你的選擇是步行, 乘坐公交車, 或自駕, 你仍然選擇步行, 即使你沒有選擇不可再用的一個選項。如果選項是在步行或開車之間,你仍然會選擇步行。人類有時行為不同。
IIA假設在協變量的條件下, 選擇是獨立的。如果違反這種假設, 選擇將是相關的。隨機係數允許選擇相關性。研究人員經常在隨機效用模型和離散選擇分析的中使用混合模型。Stata新的asmixlogit Logit命令支持各種隨機係數分布, 並允許包含特定案例變量的模型。

非參數回歸
Stata現在適合非參數回歸。在這些模型中, 不指定函數形式。指定變量並指定想要匹配的變量:
匹配項是g()。該方法不假定 g () 是線性的
聚類隨機設計和回歸模型的功耗分析
Stata現有的power命令執行功率和樣本(PSS) 分析。其功能包括PSS線性回歸和集群隨機設計 (CRDs)。現在可以添加你自己的功率和樣本大小的方法。
線性回歸的新方法包括
power oneslope,在一個簡單的線性回歸中對斜率測試執行pss。根據給定的其他研究參數計算樣本的大小或功率
power rsquared,在多元線性回歸中執行R-squared檢驗的PSS。R-squared檢驗是對測定係數 (R-squared) 的 f 檢驗。測試可以用來測試所有係數的意義, 也可以用來測試其中的一個子集。在這兩種情況下, power rsquared計算樣本大小或功率或目標R-squared給其他參數研究。
power pcorr,在多元線性回歸中執行PSS的部分相關測試。部分相關檢驗是平方偏多相關係數 f的 檢驗。該命令根據其他研究參數計算樣本大小或功率或目標平方偏相關係數。
Stata 15現在還支持集群隨機化設計:
在 CRD中, 組的受試者 (集群) 是隨機的而不是個體, 這意味著樣本大小的作用是通過數字集群和集群大小來發揮的。樣本大小確定包括給定集群大小的數量或給定集群的大小。CRD命令計算 (1) 的一個集群的數目, (2)的集群大小, 或 (3)的功率, 或最小的可檢測到的效果大小給定的其他參數。這些命令可以根據不相等的集群大小調整選項。
當指定新的選項集群時, 現有的5個 power方法將擴展到支持CRDs。它們是
對於兩個樣本方法, 還可以針對兩個組中的不相等的集群進行調整。
與所有其他功率方法一樣, 新方法允許指定參數的多個參數值, 並自動生成表格和圖形結果。
另一個新功能是可以添加自己的PSS方法。這是很容易做到的。編寫一個計算樣本大小、功率或效果大小的程序。power命令將為您完成其餘部分。它將處理選項中多個值的支持, 並且自動生成圖形和結果表。
Word和PDF文檔
現在, 使用Stata嵌入的結果生成 Word 和 PDF檔就像製作 Excel 工作表一樣容易。大多數使用者喜歡Stata 14中的putexcel,如果你也是他們中的一員,你會愛上新的putpdf和putdocx命令。他們像putexce一樣工作。可以編寫do-file來創建包含最新結果、表格和圖表的整個Word 或 PDF報表。可自動執行可重複的報告。
新的 putdocx 命令將段落、圖像和表格寫入 word 文檔 (. docx 文件)。圖像包括Stata圖形和組織的標誌。也可以設置文本對象的格式。包括字體大小、粗體、傾斜、自定義表等。
圖形顏色透明度/不透明度
到現在為止, 在另一個上麵畫一個物體, 上麵的物體蓋住下麵的物體。在計算機圖形學的行話中, Stata顏色完全不透明, 或者, 如果你喜歡不完全透明。Stata15允許控製其顏色的不透明度。
不透明度指定為一個百分比。默認情況下, Stata的顏色是100% 不透明的。
每當指定一個顏色時都可以指定不透明度,例如在mcolor ()選項中控製標記的顏色。你可以指定green%50,而不是green。你可以指定”0 255 0%50.而不是”0 255 0%50(相當於綠色)。可以自行指定%50, 使默認顏色50%不透明。但是, 不要指定%0。這是完全透明的, 也是無形的。
這裏是一個圖表,使用70 %的不透明度:
15、ICD-10-CM/PCS支持
Stata 15支持 ICD-10-CM 和 ICD-10-PCS, 由 NCHS 和CMS 提供的美國 ICD-10 代碼。Stata 15支持從2016版本開始(從2015年10月開始) 的代碼, 當它們被授權在美國使用, 並支持所有後續版本。
Stata在 1998年開始支持ICD, 從 ICD-9-CM 16版本開始, 並支持之後的每 ICD-9 版本。自2003年以來, Stata也支持 ICD-10 代碼版本。
1998年以來, Stata的ICD命令從僅僅是一個自動的有效代碼和簡短短語列表, 成為ICD代碼的整個數據管理係統。該係統甚至包括在一個數據集中管理多個ICD版本的能力!
聯邦儲備經濟數據(FRED)支持
聖路易斯聯邦儲備局向注冊用戶提供超過47萬的美國和國際經濟和金融時間序列。注冊是免費的並且很容易做。這項服務叫FRED。它包括來自84個來源的數據, 包括美聯儲、賓州世界表、歐統局和世界銀行。
Stata 15中,你可以使用Stata的GUI來訪問和下載FRED數據。可以按類別、發布或來源進行搜索或瀏覽。可以單擊選擇感興趣的係列。選擇1或選擇100。當您點擊下載”時, Stata將下載它們並將它們合並到一個內存中的單個自定義數據集中。
Stata命令行界麵也提供了這些相同的功能。命令是import fred。當追蹤月報表需要自動更新27個不同係列時, 該命令非常方便。
Stata可以訪問FRED和ALFRED。ALFRED是FRED的曆史檔案數據。
其他
在Stata功能頁麵中了解更多上述功能, 還有以下功能:
貝葉斯多級模型
門限回歸
具有隨機係數的麵板數據tobit
區間測量結果的多層回歸
刪失結果的多級Tobit回歸
麵板數據的協整測試
時間序列中多斷點的測試
多組廣義 SEM
異方差的線性回歸
Heckman風格的樣本選擇Poisson模型
具有隨機係數的麵板數據非線性模型
貝葉斯麵板數據模型
隨機係數的麵板數據區間回歸
SVG的導出
貝葉斯生存模型
零膨脹有序概率
添加您自己的電源和樣本大小的方法
貝葉斯樣本選擇模型
支持瑞典語
對DO文件編輯器的改進
流隨機數生成器
對於java插件的改進
Stata / MP更多的並行化
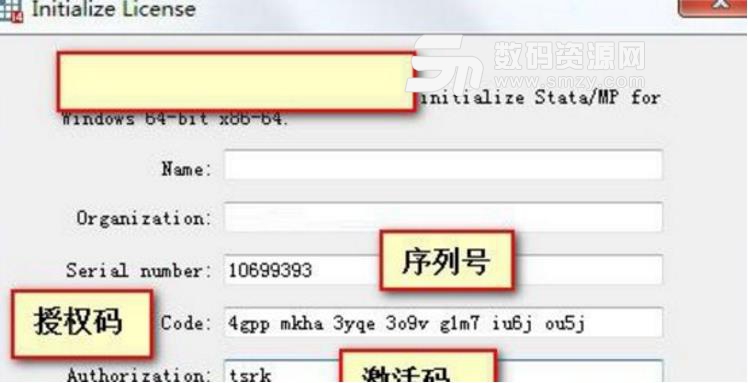
序列號 (Seri):10699393
授權碼 (Code):6irr omjb3xob $m9x k7uh u7lt y258 a51y tphc
激活碼 (Auth):vuts
Stata15永久授權碼(激活碼) 注冊版審計評估
/ 220M
 MATLAB7.0激活版(附序列號) 免費版審計評估
/ 1G
MATLAB7.0激活版(附序列號) 免費版審計評估
/ 1G
 RISK中文版(風險建模分析軟件) v7.5 免費版審計評估
/ 1M
RISK中文版(風險建模分析軟件) v7.5 免費版審計評估
/ 1M
 TableauServer2018注冊版64位授權版審計評估
/ 1G
TableauServer2018注冊版64位授權版審計評估
/ 1G
 NBA2K13巔峰時期火箭姚明MC存檔(綜合能力值為90) 最新版審計評估
/ 834K
NBA2K13巔峰時期火箭姚明MC存檔(綜合能力值為90) 最新版審計評估
/ 834K
 EViews10.0最新版(專業計量經濟學) 64位 內購版審計評估
/ 235M
EViews10.0最新版(專業計量經濟學) 64位 內購版審計評估
/ 235M
 廣東省企業所得稅申報係統(所得稅申報軟件) v2017.14 官方版審計評估
/ 28M
廣東省企業所得稅申報係統(所得稅申報軟件) v2017.14 官方版審計評估
/ 28M
 審計助手通用版(自動生成審計報告) v8.0 最新正式版審計評估
/ 11M
審計助手通用版(自動生成審計報告) v8.0 最新正式版審計評估
/ 11M
 IBM SPSS Statistics19正式版(統計分析) 中文版審計評估
/ 477M
IBM SPSS Statistics19正式版(統計分析) 中文版審計評估
/ 477M
 潤乾計算表2018官方版(附最新授權工具) 免費版審計評估
/ 195M
Stata15永久授權碼(激活碼) 注冊版審計評估
/ 220M
MATLAB7.0激活版(附序列號) 免費版審計評估
/ 1G
RISK中文版(風險建模分析軟件) v7.5 免費版審計評估
/ 1M
TableauServer2018注冊版64位授權版審計評估
/ 1G
NBA2K13巔峰時期火箭姚明MC存檔(綜合能力值為90) 最新版審計評估
/ 834K
EViews10.0最新版(專業計量經濟學) 64位 內購版審計評估
/ 235M
廣東省企業所得稅申報係統(所得稅申報軟件) v2017.14 官方版審計評估
/ 28M
審計助手通用版(自動生成審計報告) v8.0 最新正式版審計評估
/ 11M
IBM SPSS Statistics19正式版(統計分析) 中文版審計評估
/ 477M
潤乾計算表2018官方版(附最新授權工具) 免費版審計評估
/ 195M
潤乾計算表2018官方版(附最新授權工具) 免費版審計評估
/ 195M
Stata15永久授權碼(激活碼) 注冊版審計評估
/ 220M
MATLAB7.0激活版(附序列號) 免費版審計評估
/ 1G
RISK中文版(風險建模分析軟件) v7.5 免費版審計評估
/ 1M
TableauServer2018注冊版64位授權版審計評估
/ 1G
NBA2K13巔峰時期火箭姚明MC存檔(綜合能力值為90) 最新版審計評估
/ 834K
EViews10.0最新版(專業計量經濟學) 64位 內購版審計評估
/ 235M
廣東省企業所得稅申報係統(所得稅申報軟件) v2017.14 官方版審計評估
/ 28M
審計助手通用版(自動生成審計報告) v8.0 最新正式版審計評估
/ 11M
IBM SPSS Statistics19正式版(統計分析) 中文版審計評估
/ 477M
潤乾計算表2018官方版(附最新授權工具) 免費版審計評估
/ 195M





