



/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
Todo清單v2.0.0官方版京東自動搶券v1.50免費版Everything官方版v1.4.1.998最新版LOL英雄聯盟角色變大工具v1.0 綠色防封版美圖秀秀64位最新版v6.4.2.0 官方版福昕pdf編輯器去水印綠色版(圖像處理) v9.2 最新版微軟必應詞典官方版(翻譯軟件) v3.5.4.1 綠色版搜狗輸入法電腦最新版(輸入法) v9.3.0.2941 官方版網易音樂(音樂) v2.5.5.197810 電腦版 WPS Office 2019 電腦版(WPS Office ) 11.1.0.8919全能完整版想要輕鬆獲取世界一流的Web搜索引擎,那就千萬不要錯過Apache Nutch官方版!它是一款非常受歡迎的Java搜索引擎框架,能夠為廣大用戶提供全文搜索和Web爬蟲等超多功能,不僅可以建立自己內部網的搜索引擎,同時也可以針對整個網絡建立搜索引擎,對Apache Nutch官方版感興趣的朋友千萬不要錯過!
每個月取幾十億網頁
為這些網頁維護一個索引
對索引文件進行每秒上千次的搜索
提供高質量的搜索結果

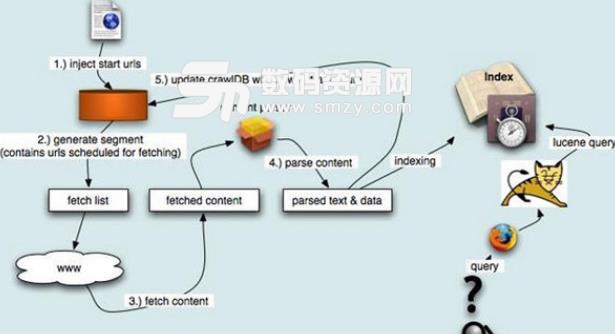
支持將起始URL集合注入到Nutch係統之中
支持生成片段文件,其中包含了將要抓取的URL地址
根據URL地址在互聯網上抓取相應的內容
解析所抓取到的網頁,並分析其中的文本和數據
根據新抓取的網頁中的URL集合來更新起始URL集合,並再次進行抓取
同時,對抓取到的網頁內容建立索引,生成索引文件存放在係統之中
首先先運行軟件,選擇File -> Import Project ->選擇apache-nutch-1.9文件夾,確定後選擇Import project from external model(Eclipse)
一直點擊next到結束,成功將項目導入project中去
源碼導入工程後,並不能執行完整的爬取。Nutch將爬取的流程切分成很多階段,每個階段分別封裝在一個類的main函數中。在外麵通過Linux Shell調用這些main函數,來完整爬取的流程。下麵我們來運行Nutch中最簡單的流程:Inject。我們知道爬蟲在初始階段,是需要人工給出一個或多個url,作為起始點(廣度遍曆樹的樹根)。Inject的作用,就是把用戶寫在文件裏的種子(一行一個url,是TextInputFormat),插入到爬蟲的URL管理文件(crawldb,是SequenceFile)中。
接下來我們按照Nutch默認的配置,需要修改Nutch的配置文件,為插件文件夾指定一個絕對路徑,修改conf/nutch-default.xml文件內容,並且保存到工程中
接下來我們就可以開始對指定的網站的信息進行完整的爬取了
 btspread中文版(磁力搜索) 網頁版搜索引擎
/ 1K
btspread中文版(磁力搜索) 網頁版搜索引擎
/ 1K
 BT磁力豬搜索引擎
/ 5M
BT磁力豬搜索引擎
/ 5M
 DiggBT引擎v2019 網頁版搜索引擎
/ 1K
DiggBT引擎v2019 網頁版搜索引擎
/ 1K
 磁力豬番號大全永久免費版搜索引擎
/ 0B
磁力豬番號大全永久免費版搜索引擎
/ 0B
 番號搜索神器(BT種子磁力搜索器) v5.9 綠色版搜索引擎
/ 1.21M
番號搜索神器(BT種子磁力搜索器) v5.9 綠色版搜索引擎
/ 1.21M
 BT磁力搜索引擎免費版(種子搜索器) v1.2.18 最新版搜索引擎
/ 806K
磁力豬BT搜索引擎
/ 5M
BT磁力搜索引擎免費版(種子搜索器) v1.2.18 最新版搜索引擎
/ 806K
磁力豬BT搜索引擎
/ 5M
 番號搜索器網頁版(迅雷P2P種子搜索) v1.0 最新版搜索引擎
/ 4K
番號搜索器網頁版(迅雷P2P種子搜索) v1.0 最新版搜索引擎
/ 4K
 BT兔子免費版(磁力搜索) v1.0 官方版搜索引擎
/ 3M
BT兔子免費版(磁力搜索) v1.0 官方版搜索引擎
/ 3M
 資源貓番號搜索神器(資源貓資源搜索) 最新版搜索引擎
/ 5M
btspread中文版(磁力搜索) 網頁版搜索引擎
/ 1K
磁力豬番號大全永久免費版搜索引擎
/ 0B
BT磁力豬搜索引擎
/ 5M
DiggBT引擎v2019 網頁版搜索引擎
/ 1K
BT磁力搜索引擎免費版(種子搜索器) v1.2.18 最新版搜索引擎
/ 806K
番號搜索神器(BT種子磁力搜索器) v5.9 綠色版搜索引擎
/ 1.21M
磁力豬BT搜索引擎
/ 5M
番號搜索器網頁版(迅雷P2P種子搜索) v1.0 最新版搜索引擎
/ 4K
BT兔子免費版(磁力搜索) v1.0 官方版搜索引擎
/ 3M
資源貓番號搜索神器(資源貓資源搜索) 最新版搜索引擎
/ 5M
資源貓番號搜索神器(資源貓資源搜索) 最新版搜索引擎
/ 5M
btspread中文版(磁力搜索) 網頁版搜索引擎
/ 1K
磁力豬番號大全永久免費版搜索引擎
/ 0B
BT磁力豬搜索引擎
/ 5M
DiggBT引擎v2019 網頁版搜索引擎
/ 1K
BT磁力搜索引擎免費版(種子搜索器) v1.2.18 最新版搜索引擎
/ 806K
番號搜索神器(BT種子磁力搜索器) v5.9 綠色版搜索引擎
/ 1.21M
磁力豬BT搜索引擎
/ 5M
番號搜索器網頁版(迅雷P2P種子搜索) v1.0 最新版搜索引擎
/ 4K
BT兔子免費版(磁力搜索) v1.0 官方版搜索引擎
/ 3M
資源貓番號搜索神器(資源貓資源搜索) 最新版搜索引擎
/ 5M





