



/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
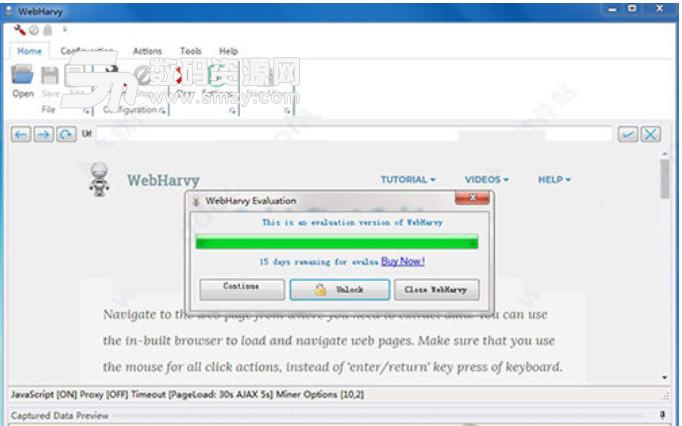
Todo清單v2.0.0官方版京東自動搶券v1.50免費版Everything官方版v1.4.1.998最新版LOL英雄聯盟角色變大工具v1.0 綠色防封版美圖秀秀64位最新版v6.4.2.0 官方版福昕pdf編輯器去水印綠色版(圖像處理) v9.2 最新版微軟必應詞典官方版(翻譯軟件) v3.5.4.1 綠色版搜狗輸入法電腦最新版(輸入法) v9.3.0.2941 官方版網易音樂(音樂) v2.5.5.197810 電腦版 WPS Office 2019 電腦版(WPS Office ) 11.1.0.8919全能完整版如何不守在電腦前就可以輕鬆獲取網頁的數據圖片信息呢? 小編為你推薦WebHarvy正式版! 它是一款非常好用的網頁數據抓取工具, 在其中我們可以抓取網頁的文件以及圖片信息數據,並且操作方法十分的簡單, 輕鬆滿足用戶的網頁抓取需求, 喜歡就來下載WebHarvy正式版吧!
智能識別模式
WebHarvy自動識別網頁中出現的數據模式。所以,如果你需要從一個網頁刮項目(姓名,地址,電子郵件,價格等)的列表,你不需要做任何額外的配置。如果數據重複,WebHarvy會自動刮。
導出捕獲的數據
可以保存從各種格式的網頁中提取的數據。 WebHarvy網站刮板的當前版本允許你導出的刮數據作為XML,CSV,JSON或TSV文件。您還可以刮下數據導出到一個SQL數據庫。
從多個頁麵提取
通常網頁顯示數據,如在多個頁麵中的產品目錄。 WebHarvy可以自動抓取並從多個網頁中提取數據。隻是指出了“鏈接到下一頁'和WebHarvy網站刮板將自動刮從所有頁麵的數據。
直觀化的操作界麵
WebHarvy是一個可視化的網頁提取工具。其實完全沒有必要編寫任何腳本或代碼用來提取數據。使用webharvy的內置瀏覽器瀏覽網頁。您可以選擇用鼠標點擊來提取數據。它是那麼容易!
基於關鍵字的提取
基於關鍵字的提取可讓您捕捉從搜索結果頁麵輸入關鍵字的列表數據。您創建的配置將被自動重複所有給定輸入關鍵字,而挖掘的數據。可以指定任意數量的輸入關鍵字
提取分類
WebHarvy網站刮板允許您從一個鏈接列表,從而導致一個網站內的相似頁麵抽取數據。這使您可以使用一個單一的配置刮網站內的類別或小節。
使用正則表達式提取
WebHarvy可以應用正則表達式(正則表達式)在文本或網頁的HTML源代碼,並提取去匹配的部分。這種強大的技術為您提供了更多的靈活性,同時拚搶的數據。
 冰點還原精靈許可證8.3最新版(永久性密鑰) 標準版係統備份
/ 15M
冰點還原精靈許可證8.3最新版(永久性密鑰) 標準版係統備份
/ 15M
 vivo互傳PC端v3.1.5 官方版係統備份
/ 102M
vivo互傳PC端v3.1.5 官方版係統備份
/ 102M
 Reboot Restore Rx(係統備份還原工具)v11.2官方版係統備份
/ 49M
Reboot Restore Rx(係統備份還原工具)v11.2官方版係統備份
/ 49M
 萬能解析免費版(全網視頻萬能解析工具) v1.0 官方版係統備份
/ 508K
萬能解析免費版(全網視頻萬能解析工具) v1.0 官方版係統備份
/ 508K
 Blobsaver(文件備份軟件)v2.4.0係統備份
/ 3.80M
Blobsaver(文件備份軟件)v2.4.0係統備份
/ 3.80M
 Coolmuster Mobile Transfer(手機數據轉移工具)v2.4.46.0官方版係統備份
/ 28.60M
Coolmuster Mobile Transfer(手機數據轉移工具)v2.4.46.0官方版係統備份
/ 28.60M
 冰點還原精靈(附注冊機)免費(DeepFreeze)v8.55 企業破解版係統備份
/ 30M
冰點還原精靈(附注冊機)免費(DeepFreeze)v8.55 企業破解版係統備份
/ 30M
 冰點還原精靈免注冊版(DeepFreeze) v8.3 個人中文版係統備份
/ 45M
冰點還原精靈免注冊版(DeepFreeze) v8.3 個人中文版係統備份
/ 45M
 u盤安裝android係統(鳳凰安卓係統PC版) v1.0.4 最新版係統備份
/ 508M
u盤安裝android係統(鳳凰安卓係統PC版) v1.0.4 最新版係統備份
/ 508M
 Acronis True Image2018破解版(附注冊機) v22.5 中文免費版係統備份
/ 531M
冰點還原精靈許可證8.3最新版(永久性密鑰) 標準版係統備份
/ 15M
vivo互傳PC端v3.1.5 官方版係統備份
/ 102M
Reboot Restore Rx(係統備份還原工具)v11.2官方版係統備份
/ 49M
萬能解析免費版(全網視頻萬能解析工具) v1.0 官方版係統備份
/ 508K
Blobsaver(文件備份軟件)v2.4.0係統備份
/ 3.80M
Coolmuster Mobile Transfer(手機數據轉移工具)v2.4.46.0官方版係統備份
/ 28.60M
冰點還原精靈(附注冊機)免費(DeepFreeze)v8.55 企業破解版係統備份
/ 30M
冰點還原精靈免注冊版(DeepFreeze) v8.3 個人中文版係統備份
/ 45M
u盤安裝android係統(鳳凰安卓係統PC版) v1.0.4 最新版係統備份
/ 508M
Acronis True Image2018破解版(附注冊機) v22.5 中文免費版係統備份
/ 531M
冰點還原精靈許可證8.3最新版(永久性密鑰) 標準版係統備份
vivo互傳PC端v3.1.5 官方版係統備份
Reboot Restore Rx(係統備份還原工具)v11.2官方版係統備份
萬能解析免費版(全網視頻萬能解析工具) v1.0 官方版係統備份
Blobsaver(文件備份軟件)v2.4.0係統備份
Coolmuster Mobile Transfer(手機數據轉移工具)v2.4.46.0官方版係統備份
冰點還原精靈(附注冊機)免費(DeepFreeze)v8.55 企業破解版係統備份
冰點還原精靈免注冊版(DeepFreeze) v8.3 個人中文版係統備份
u盤安裝android係統(鳳凰安卓係統PC版) v1.0.4 最新版係統備份
Acronis True Image2018破解版(附注冊機) v22.5 中文免費版係統備份
/ 531M
冰點還原精靈許可證8.3最新版(永久性密鑰) 標準版係統備份
/ 15M
vivo互傳PC端v3.1.5 官方版係統備份
/ 102M
Reboot Restore Rx(係統備份還原工具)v11.2官方版係統備份
/ 49M
萬能解析免費版(全網視頻萬能解析工具) v1.0 官方版係統備份
/ 508K
Blobsaver(文件備份軟件)v2.4.0係統備份
/ 3.80M
Coolmuster Mobile Transfer(手機數據轉移工具)v2.4.46.0官方版係統備份
/ 28.60M
冰點還原精靈(附注冊機)免費(DeepFreeze)v8.55 企業破解版係統備份
/ 30M
冰點還原精靈免注冊版(DeepFreeze) v8.3 個人中文版係統備份
/ 45M
u盤安裝android係統(鳳凰安卓係統PC版) v1.0.4 最新版係統備份
/ 508M
Acronis True Image2018破解版(附注冊機) v22.5 中文免費版係統備份
/ 531M
冰點還原精靈許可證8.3最新版(永久性密鑰) 標準版係統備份
vivo互傳PC端v3.1.5 官方版係統備份
Reboot Restore Rx(係統備份還原工具)v11.2官方版係統備份
萬能解析免費版(全網視頻萬能解析工具) v1.0 官方版係統備份
Blobsaver(文件備份軟件)v2.4.0係統備份
Coolmuster Mobile Transfer(手機數據轉移工具)v2.4.46.0官方版係統備份
冰點還原精靈(附注冊機)免費(DeepFreeze)v8.55 企業破解版係統備份
冰點還原精靈免注冊版(DeepFreeze) v8.3 個人中文版係統備份
u盤安裝android係統(鳳凰安卓係統PC版) v1.0.4 最新版係統備份


