

/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
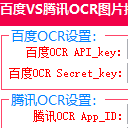
Todo清單v2.0.0官方版京東自動搶券v1.50免費版Everything官方版v1.4.1.998最新版LOL英雄聯盟角色變大工具v1.0 綠色防封版美圖秀秀64位最新版v6.4.2.0 官方版福昕pdf編輯器去水印綠色版(圖像處理) v9.2 最新版微軟必應詞典官方版(翻譯軟件) v3.5.4.1 綠色版搜狗輸入法電腦最新版(輸入法) v9.3.0.2941 官方版網易音樂(音樂) v2.5.5.197810 電腦版 WPS Office 2019 電腦版(WPS Office ) 11.1.0.8919全能完整版非常專業的文字識別軟件,推薦給有需要的用戶們,百度VS騰訊OCR圖片批量識別轉文字pc版該軟件支持批量識別圖片文字,百度ocr文字識別工具,對於不同的圖像格式,有著不同的存儲格式,非常準確的識別圖像的文字,采用優化的光學字符識別係統,功能非常豐富,百度VS騰訊OCR圖片批量識別轉文字pc版期待你的使用

【字符識別】
這一研究,已經是很早的事情了,比較早有模板匹配,後來以特征提取為主,由於文字的位移,筆畫的粗細,斷筆,粘連,旋轉等因素的影響,極大影響特征的提取的難度。
【版麵恢複】
人們希望識別後的文字,仍然像原文檔圖片那樣排列著,段落不變,位置不變,順序不變,的輸出到word文檔,pdf文檔等,這一過程就叫做版麵恢複。
【後處理、校對】
根據特定的語言上下文的關係,對識別結果進行較正,就是後處理。
【圖像輸入、預處理】
圖像輸入:對於不同的圖像格式,有著不同的存儲格式,不同的壓縮方式,目前有OpenCV,CxImage等開源項目 。預處理:主要包括二值化,噪聲去除,傾斜較正等
【二值化】
對攝像頭拍攝的圖片,大多數是彩色圖像,彩色圖像所含信息量巨大,對於圖片的內容,我們可以簡單的分為前景與背景,為了讓計算機更快的,更好的識別文字,我們需要先對彩色圖進行處理,使圖片隻前景信息與背景信息,可以簡單的定義前景信息為黑色,背景信息為白色,這就是二值化圖了。
【噪聲去除】
對於不同的文檔,我們對噪聲的定義可以不同,根據噪聲的特征進行去噪,就叫做噪聲去除
【傾斜較正】
由於一般用戶,在拍照文檔時,都比較隨意,因此拍照出來的圖片不可避免的產生傾斜,這就需要文字識別軟件進行較正。
【版麵分析】
將文檔圖片分段落,分行的過程就叫做版麵分析,由於實際文檔的多樣性,複雜性,因此,目前還沒有一個固定的,最優的切割模型。
【字符切割】
由於拍照條件的限製,經常造成字符粘連,斷筆,因此極大限製了識別係統的性能,這就需要文字識別軟件有字符切割功能。
1 下載完成後不要在壓縮包內運行軟件直接使用,先解壓;
2 軟件同時支持32位64位運行環境;
3 如果軟件無法正常打開,請右鍵使用管理員模式運行。
軟件停止更新。
修正個別電腦識別隻顯示識別一張圖的問題。
 ALLTOALL在線文件轉換工具(凹凸凹在線文件轉換) 官方版文字處理
/ 1K
ALLTOALL在線文件轉換工具(凹凸凹在線文件轉換) 官方版文字處理
/ 1K
 EverEdit無限試用補丁(無需注冊碼) v4.0 最新版文字處理
/ 34K
EverEdit無限試用補丁(無需注冊碼) v4.0 最新版文字處理
/ 34K
 EasiSign互動簽名軟件綠色版(電子簽名軟件) v1.0 免費版文字處理
/ 116K
EasiSign互動簽名軟件綠色版(電子簽名軟件) v1.0 免費版文字處理
/ 116K
 EditPlus5漢化補丁(完美漢化) 免費版文字處理
/ 1M
EditPlus5漢化補丁(完美漢化) 免費版文字處理
/ 1M
 百度OCR文字識別免費版v2017 最新版 文字處理
/ 2M
百度OCR文字識別免費版v2017 最新版 文字處理
/ 2M
 字魂綠色版(字體工具) v1.1.9 官方版文字處理
/ 45M
字魂綠色版(字體工具) v1.1.9 官方版文字處理
/ 45M
 noteexpress個人免費版(文獻檢索管理應用) v3.0 綠色穩定版文字處理
/ 72M
noteexpress個人免費版(文獻檢索管理應用) v3.0 綠色穩定版文字處理
/ 72M
 網頁文字抓取工具綠色版(抓取網頁文字) v1.0 免費版文字處理
/ 10K
網頁文字抓取工具綠色版(抓取網頁文字) v1.0 免費版文字處理
/ 10K
 寶馬一鍵刷隱藏軟件綠色版(BMWAiCoder) v5.0 中文版文字處理
/ 45M
寶馬一鍵刷隱藏軟件綠色版(BMWAiCoder) v5.0 中文版文字處理
/ 45M
 ksc字幕製作軟件(製作字幕) v3.5.2.683 官方版文字處理
/ 1M
ALLTOALL在線文件轉換工具(凹凸凹在線文件轉換) 官方版文字處理
/ 1K
EverEdit無限試用補丁(無需注冊碼) v4.0 最新版文字處理
/ 34K
EasiSign互動簽名軟件綠色版(電子簽名軟件) v1.0 免費版文字處理
/ 116K
EditPlus5漢化補丁(完美漢化) 免費版文字處理
/ 1M
百度OCR文字識別免費版v2017 最新版 文字處理
/ 2M
字魂綠色版(字體工具) v1.1.9 官方版文字處理
/ 45M
noteexpress個人免費版(文獻檢索管理應用) v3.0 綠色穩定版文字處理
/ 72M
網頁文字抓取工具綠色版(抓取網頁文字) v1.0 免費版文字處理
/ 10K
寶馬一鍵刷隱藏軟件綠色版(BMWAiCoder) v5.0 中文版文字處理
/ 45M
ksc字幕製作軟件(製作字幕) v3.5.2.683 官方版文字處理
/ 1M
ALLTOALL在線文件轉換工具(凹凸凹在線文件轉換) 官方版文字處理
EverEdit無限試用補丁(無需注冊碼) v4.0 最新版文字處理
EasiSign互動簽名軟件綠色版(電子簽名軟件) v1.0 免費版文字處理
EditPlus5漢化補丁(完美漢化) 免費版文字處理
百度OCR文字識別免費版v2017 最新版 文字處理
字魂綠色版(字體工具) v1.1.9 官方版文字處理
noteexpress個人免費版(文獻檢索管理應用) v3.0 綠色穩定版文字處理
網頁文字抓取工具綠色版(抓取網頁文字) v1.0 免費版文字處理
寶馬一鍵刷隱藏軟件綠色版(BMWAiCoder) v5.0 中文版文字處理
ksc字幕製作軟件(製作字幕) v3.5.2.683 官方版文字處理
/ 1M
ALLTOALL在線文件轉換工具(凹凸凹在線文件轉換) 官方版文字處理
/ 1K
EverEdit無限試用補丁(無需注冊碼) v4.0 最新版文字處理
/ 34K
EasiSign互動簽名軟件綠色版(電子簽名軟件) v1.0 免費版文字處理
/ 116K
EditPlus5漢化補丁(完美漢化) 免費版文字處理
/ 1M
百度OCR文字識別免費版v2017 最新版 文字處理
/ 2M
字魂綠色版(字體工具) v1.1.9 官方版文字處理
/ 45M
noteexpress個人免費版(文獻檢索管理應用) v3.0 綠色穩定版文字處理
/ 72M
網頁文字抓取工具綠色版(抓取網頁文字) v1.0 免費版文字處理
/ 10K
寶馬一鍵刷隱藏軟件綠色版(BMWAiCoder) v5.0 中文版文字處理
/ 45M
ksc字幕製作軟件(製作字幕) v3.5.2.683 官方版文字處理
/ 1M
ALLTOALL在線文件轉換工具(凹凸凹在線文件轉換) 官方版文字處理
EverEdit無限試用補丁(無需注冊碼) v4.0 最新版文字處理
EasiSign互動簽名軟件綠色版(電子簽名軟件) v1.0 免費版文字處理
EditPlus5漢化補丁(完美漢化) 免費版文字處理
百度OCR文字識別免費版v2017 最新版 文字處理
字魂綠色版(字體工具) v1.1.9 官方版文字處理
noteexpress個人免費版(文獻檢索管理應用) v3.0 綠色穩定版文字處理
網頁文字抓取工具綠色版(抓取網頁文字) v1.0 免費版文字處理
寶馬一鍵刷隱藏軟件綠色版(BMWAiCoder) v5.0 中文版文字處理