/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
Todo清單v2.0.0官方版京東自動搶券v1.50免費版Everything官方版v1.4.1.998最新版LOL英雄聯盟角色變大工具v1.0 綠色防封版美圖秀秀64位最新版v6.4.2.0 官方版福昕pdf編輯器去水印綠色版(圖像處理) v9.2 最新版微軟必應詞典官方版(翻譯軟件) v3.5.4.1 綠色版搜狗輸入法電腦最新版(輸入法) v9.3.0.2941 官方版網易音樂(音樂) v2.5.5.197810 電腦版 WPS Office 2019 電腦版(WPS Office ) 11.1.0.8919全能完整版非常出色的OCR文字識別係統,尚書七號OCR完全版可以掃描票據、書刊以及表格等,將它們上麵的文字準確識別出來,以一種比較好的格式呈現。無論是什麼字體,尚書七號OCR完全版都可以快速識別,有需要的朋友們快來下載使用吧,別錯過了哦!
1、識別字體種類
能識別宋體、仿宋、楷、黑、魏碑、隸書、圓體、行楷等一百多種字體,並支持多種字體混排。
2、識別字符
簡體字符集:國標GB2312-80的全部一、二級漢字6800多個。
3、純英文字符集
簡繁字集:除了簡體漢字外,還可以混識台灣繁體字5400多個以及香港繁體字和GBK漢字。
4、識別字號初號
小六號字體
5、表格識別
可以自動判斷、拆分、識別和還原各種通用型印刷體表格。
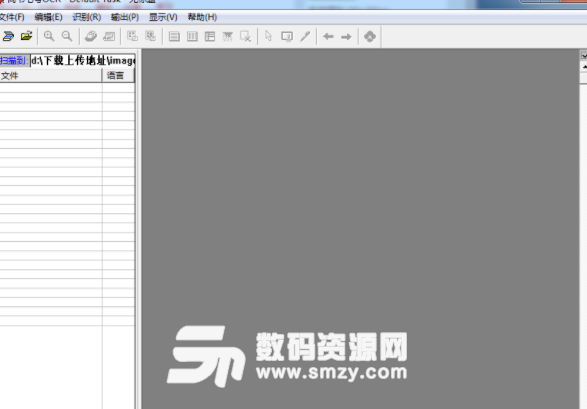
1、選擇尚書7號軟件中的“編輯”菜單下的“自動傾斜校正”,讓尚書7號軟件對掃描進來的圖像作相應的旋轉,以保證圖像中的文字是水平排列,而非傾斜。因為太過傾斜的文字,將影響到尚書軟件的識別效果。
2、打開尚書7號OCR的“文件”采單下的“選擇掃描儀”,選擇對應掃描儀的驅動“MICROTEK SCANWIZARD 5”的選項。並選擇“確定”。
3、選擇“文件”菜單下的“掃描”,將打開掃描儀的驅動。
4、請注意選擇SCANWIZARD 5軟件中,左麵“設置”窗口中的“圖像類型”,請選擇“RGB色彩”或者“灰階”的類型,並注意掃描儀分辨率是300PPI。
5、當用戶作完“預覽”後,設置需要掃描的範圍,就可以點擊“掃描”按鈕,掃描儀將開始掃描的工作。
將掃描好的文件,直接傳遞到尚書7號OCR默認的目錄中(默認的存儲圖像文件的目錄是用戶計算機C盤下的SHOCR2002目錄下的IMAGE目錄)。
掃描完畢後,請用戶關閉掉掃描儀驅動程序SCANWIZARD
用戶可以看到需要掃描的文件已經傳遞給尚書7號中,默認的文件名是HW001.JPG。
6、版麵分析完畢後,用戶可以看到對應的文字塊,都有對應的識別框被選擇
請注意,對應的識別框,其屬性是否正確。識別框分別有“橫欄”、“豎欄”、“表格”和“圖像”等四種屬性,分別有四種不同顏色的選框來表示
7、核對無誤後,用戶可以使用“識別”菜單下的“開始識別”按鈕。
此時實際上已經進入文字校對狀態
8、當用戶校對完畢後,或者不在尚書7號內作校對,用戶可以選擇“輸出”菜單下的“到指定格式文件”。
用戶可以看到,識別的結果,有TXT、RTF、HTML、XLS等格式可以選擇。
默認的輸出的目錄是用戶計算機C盤下的SHOCR2002目錄下的OUTPUT目錄。
用戶選擇一個對應的文件名,就可以存盤了。
為了方便,用戶可以選擇“輸出到外部編輯器”的選項,這樣存盤的同時,尚書7號OCR會自動調出對應的編輯軟件,如TXT存盤可以自動調用Notepad軟件,RTF存盤將自動調用word軟件,XLS存盤將自動調用EXCEL軟件。
 ALLTOALL在線文件轉換工具(凹凸凹在線文件轉換) 官方版文字處理
/ 1K
ALLTOALL在線文件轉換工具(凹凸凹在線文件轉換) 官方版文字處理
/ 1K
 EverEdit無限試用補丁(無需注冊碼) v4.0 最新版文字處理
/ 34K
EverEdit無限試用補丁(無需注冊碼) v4.0 最新版文字處理
/ 34K
 EasiSign互動簽名軟件綠色版(電子簽名軟件) v1.0 免費版文字處理
/ 116K
EasiSign互動簽名軟件綠色版(電子簽名軟件) v1.0 免費版文字處理
/ 116K
 EditPlus5漢化補丁(完美漢化) 免費版文字處理
/ 1M
EditPlus5漢化補丁(完美漢化) 免費版文字處理
/ 1M
 百度OCR文字識別免費版v2017 最新版 文字處理
/ 2M
百度OCR文字識別免費版v2017 最新版 文字處理
/ 2M
 字魂綠色版(字體工具) v1.1.9 官方版文字處理
/ 45M
字魂綠色版(字體工具) v1.1.9 官方版文字處理
/ 45M
 noteexpress個人免費版(文獻檢索管理應用) v3.0 綠色穩定版文字處理
/ 72M
noteexpress個人免費版(文獻檢索管理應用) v3.0 綠色穩定版文字處理
/ 72M
 網頁文字抓取工具綠色版(抓取網頁文字) v1.0 免費版文字處理
/ 10K
網頁文字抓取工具綠色版(抓取網頁文字) v1.0 免費版文字處理
/ 10K
 寶馬一鍵刷隱藏軟件綠色版(BMWAiCoder) v5.0 中文版文字處理
/ 45M
寶馬一鍵刷隱藏軟件綠色版(BMWAiCoder) v5.0 中文版文字處理
/ 45M
 ksc字幕製作軟件(製作字幕) v3.5.2.683 官方版文字處理
/ 1M
ALLTOALL在線文件轉換工具(凹凸凹在線文件轉換) 官方版文字處理
/ 1K
EverEdit無限試用補丁(無需注冊碼) v4.0 最新版文字處理
/ 34K
EasiSign互動簽名軟件綠色版(電子簽名軟件) v1.0 免費版文字處理
/ 116K
EditPlus5漢化補丁(完美漢化) 免費版文字處理
/ 1M
百度OCR文字識別免費版v2017 最新版 文字處理
/ 2M
字魂綠色版(字體工具) v1.1.9 官方版文字處理
/ 45M
noteexpress個人免費版(文獻檢索管理應用) v3.0 綠色穩定版文字處理
/ 72M
網頁文字抓取工具綠色版(抓取網頁文字) v1.0 免費版文字處理
/ 10K
寶馬一鍵刷隱藏軟件綠色版(BMWAiCoder) v5.0 中文版文字處理
/ 45M
ksc字幕製作軟件(製作字幕) v3.5.2.683 官方版文字處理
/ 1M
ALLTOALL在線文件轉換工具(凹凸凹在線文件轉換) 官方版文字處理
EverEdit無限試用補丁(無需注冊碼) v4.0 最新版文字處理
EasiSign互動簽名軟件綠色版(電子簽名軟件) v1.0 免費版文字處理
EditPlus5漢化補丁(完美漢化) 免費版文字處理
百度OCR文字識別免費版v2017 最新版 文字處理
字魂綠色版(字體工具) v1.1.9 官方版文字處理
noteexpress個人免費版(文獻檢索管理應用) v3.0 綠色穩定版文字處理
網頁文字抓取工具綠色版(抓取網頁文字) v1.0 免費版文字處理
寶馬一鍵刷隱藏軟件綠色版(BMWAiCoder) v5.0 中文版文字處理
ksc字幕製作軟件(製作字幕) v3.5.2.683 官方版文字處理
/ 1M
ALLTOALL在線文件轉換工具(凹凸凹在線文件轉換) 官方版文字處理
/ 1K
EverEdit無限試用補丁(無需注冊碼) v4.0 最新版文字處理
/ 34K
EasiSign互動簽名軟件綠色版(電子簽名軟件) v1.0 免費版文字處理
/ 116K
EditPlus5漢化補丁(完美漢化) 免費版文字處理
/ 1M
百度OCR文字識別免費版v2017 最新版 文字處理
/ 2M
字魂綠色版(字體工具) v1.1.9 官方版文字處理
/ 45M
noteexpress個人免費版(文獻檢索管理應用) v3.0 綠色穩定版文字處理
/ 72M
網頁文字抓取工具綠色版(抓取網頁文字) v1.0 免費版文字處理
/ 10K
寶馬一鍵刷隱藏軟件綠色版(BMWAiCoder) v5.0 中文版文字處理
/ 45M
ksc字幕製作軟件(製作字幕) v3.5.2.683 官方版文字處理
/ 1M
ALLTOALL在線文件轉換工具(凹凸凹在線文件轉換) 官方版文字處理
EverEdit無限試用補丁(無需注冊碼) v4.0 最新版文字處理
EasiSign互動簽名軟件綠色版(電子簽名軟件) v1.0 免費版文字處理
EditPlus5漢化補丁(完美漢化) 免費版文字處理
百度OCR文字識別免費版v2017 最新版 文字處理
字魂綠色版(字體工具) v1.1.9 官方版文字處理
noteexpress個人免費版(文獻檢索管理應用) v3.0 綠色穩定版文字處理
網頁文字抓取工具綠色版(抓取網頁文字) v1.0 免費版文字處理
寶馬一鍵刷隱藏軟件綠色版(BMWAiCoder) v5.0 中文版文字處理