/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
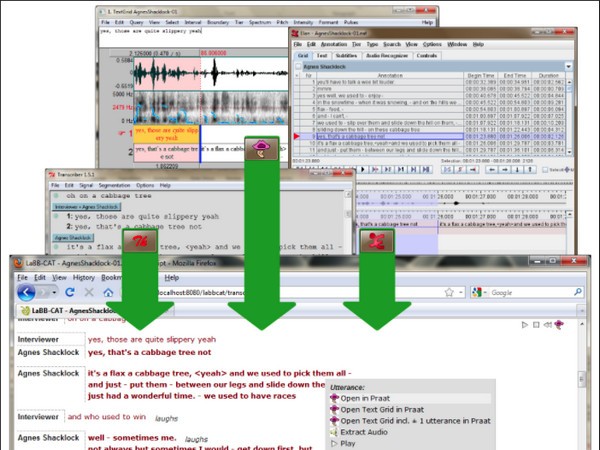
Todo清單v2.0.0官方版京東自動搶券v1.50免費版Everything官方版v1.4.1.998最新版LOL英雄聯盟角色變大工具v1.0 綠色防封版美圖秀秀64位最新版v6.4.2.0 官方版福昕pdf編輯器去水印綠色版(圖像處理) v9.2 最新版微軟必應詞典官方版(翻譯軟件) v3.5.4.1 綠色版搜狗輸入法電腦最新版(輸入法) v9.3.0.2941 官方版網易音樂(音樂) v2.5.5.197810 電腦版 WPS Office 2019 電腦版(WPS Office ) 11.1.0.8919全能完整版LABB-CAT是一款基於瀏覽器的語言學研究工具,它可以存儲錄音和正則表達式的可搜索的訪談文字記錄,搜索結果、整個筆錄和媒體,可以以各種格式查看或導出。
LIWC比較
結合CELEX的時間排列信息和音節數,可以計算出不同領域的語音率。
每分鍾的音節數,行和轉彎的音節數
斯坦福解析器
在Stanford Parser的幫助下,可以為轉錄本生成可編輯的句法樹。
跨越句法成分的注釋。
解析樹表示法
腳本
腳本可以用Python或Javascript編寫,以執行arbtrary計算和注釋任務。
用於計算對偶變異性指數的Python腳本
IBM Watson人格洞察力
LaBB-CAT可以與IBM Watson的Personality Insights網絡服務集成,對抄本進行人格分析。
手動注釋
注釋可以手動添加,比如說。
主題標簽
針對單個單詞的文本標簽
時間點或區間可以使用Praat進行注釋。
使用Praat對點進行標注
檢索
一旦記錄本和注釋到位,就可以對符合特定標準的記錄本進行搜索(例如,基於發言者的年齡/性別、記錄本所屬的語料庫等)。
按屬性過濾發言者
當發言者被選中後,可以在不同的層中搜索他們的語句,以尋找文本或常規表達。
在 "成人 "話題中搜索 "the",然後在音素層搜索以I、E、i或@開頭的單詞。
這將返回與查詢相匹配的所選抄本中所有語句的列表。
搜索結果
如果需要,可以將此列表連同相關的演講者和注釋信息直接導出到csv文件,以便在Excel或R中進行進一步分析。
搜索結果
或者可以提取音頻樣本進行分析。
從結果中提取音頻
或者可以直接使用EMU-webApp編輯語句注釋和對齊。
使用EMU-webApp編輯手機對齊。
如果語句已被強製對齊,可以用Praat對目標語段進行批量處理。
用Praat進行批量處理,以提取形體和其他聲學措施。
批量Praat處理可以包括您自己的自定義Praat腳本。
自定義Praat腳本,用於搜索結果的批量處理。
另外,點擊搜索返回的語句,就會產生有關發言者的完整文字記錄,與相關語句一起置於屏幕頂部。可以點擊謄本的任何部分,並播放媒體的相應部分。
交互式文字稿
直接從交互式轉錄頁麵播放媒體,顯示其他注釋層,提取該行的音頻,或在 Praat 中打開包含注釋的相應 TextGrid。可以添加、編輯或刪除注釋,並調整對齊方式。
媒體和記錄本的存儲
LaBB-CAT本質上是一個音頻/視頻記錄的時間對齊謄本的存儲庫。 可使用Transcriber、Praat或ELAN(可用於創建一個文件,將謄本文本與音頻/視頻記錄中的相應位置對齊)製作時間對齊的謄本。然後,謄本被上傳到LaBB-CAT,它允許存儲有關發言人和謄本的附加信息。
來自Transcriber、Praat或ELAN的謄本。
征求意見的任務
您還可以定義誘導任務,包括提示參與者閱讀和問題,讓他們回答。
當參與者完成任務時(使用他們的瀏覽器或移動設備),他們的語音會被記錄下來並自動直接上傳到LaBB-CAT。
自動注釋
結合信號數據、原始正字轉寫本以及一些第三方數據和工具,可以對轉寫本進行自動標注,例如。
詞彙標簽
來自CELEX的注釋借助CELEX的數據,可以用更多的數據自動注釋單詞。
語音學
教學大綱
形態學
語氣
頻率
其他詞典也可以整合,包括CMU發音詞典和Unisyn詞典。
強製對齊
在HTK或WebMAUS的幫助下,在語句層麵對齊的抄本可以強製對齊到詞和段層麵。
用HTK強製對齊
統計層
LaBB-CAT數據庫本身的詞頻數據可以直接對每個詞進行計算和標注。
詞頻層
語言學探究和字數"(LIWC)可以用來比較語料庫和參考語料庫。
 三字經童聲朗讀mp3(三字經學習) 完整版文科工具
/ 2M
三字經童聲朗讀mp3(三字經學習) 完整版文科工具
/ 2M
 字帖生成軟件(小學生田字格字帖製作) v2019文科工具
/ 95M
字帖生成軟件(小學生田字格字帖製作) v2019文科工具
/ 95M
 文淵閣四庫全書djvu影印版文科工具
/ 10G
文淵閣四庫全書djvu影印版文科工具
/ 10G
 漢語教程第一冊上冊(含答案)pdf高清版(非常適合漢語研究) 掃描電子版文科工具
/ 2M
漢語教程第一冊上冊(含答案)pdf高清版(非常適合漢語研究) 掃描電子版文科工具
/ 2M
 作文格子紙a3a4模板(作文格子紙模板) v1.0 綠色版文科工具
/ 10.80M
作文格子紙a3a4模板(作文格子紙模板) v1.0 綠色版文科工具
/ 10.80M
 《知雲文獻翻譯》電腦版v5.4.3.2文科工具
/ 13.71M
《知雲文獻翻譯》電腦版v5.4.3.2文科工具
/ 13.71M
 小學語文作業生成器免費版(自動生成語文題) v1.2 中文綠色版文科工具
/ 602K
小學語文作業生成器免費版(自動生成語文題) v1.2 中文綠色版文科工具
/ 602K
 PaperEasy論文修改助手(論文查重降重) v4.0 免費版文科工具
/ 1M
PaperEasy論文修改助手(論文查重降重) v4.0 免費版文科工具
/ 1M
 公文寫作神器綠色版(文科工具) v2.7.0.16PC 免費版文科工具
/ 9M
公文寫作神器綠色版(文科工具) v2.7.0.16PC 免費版文科工具
/ 9M
 電腦版公文寫作神器(全自動搜索生成) v1.0 免費版文科工具
/ 29M
三字經童聲朗讀mp3(三字經學習) 完整版文科工具
/ 2M
字帖生成軟件(小學生田字格字帖製作) v2019文科工具
/ 95M
文淵閣四庫全書djvu影印版文科工具
/ 10G
漢語教程第一冊上冊(含答案)pdf高清版(非常適合漢語研究) 掃描電子版文科工具
/ 2M
電腦版公文寫作神器(全自動搜索生成) v1.0 免費版文科工具
/ 29M
作文格子紙a3a4模板(作文格子紙模板) v1.0 綠色版文科工具
/ 10.80M
《知雲文獻翻譯》電腦版v5.4.3.2文科工具
/ 13.71M
小學語文作業生成器免費版(自動生成語文題) v1.2 中文綠色版文科工具
/ 602K
PaperEasy論文修改助手(論文查重降重) v4.0 免費版文科工具
/ 1M
公文寫作神器綠色版(文科工具) v2.7.0.16PC 免費版文科工具
/ 9M
電腦版公文寫作神器(全自動搜索生成) v1.0 免費版文科工具
/ 29M
三字經童聲朗讀mp3(三字經學習) 完整版文科工具
/ 2M
字帖生成軟件(小學生田字格字帖製作) v2019文科工具
/ 95M
文淵閣四庫全書djvu影印版文科工具
/ 10G
漢語教程第一冊上冊(含答案)pdf高清版(非常適合漢語研究) 掃描電子版文科工具
/ 2M
電腦版公文寫作神器(全自動搜索生成) v1.0 免費版文科工具
/ 29M
作文格子紙a3a4模板(作文格子紙模板) v1.0 綠色版文科工具
/ 10.80M
《知雲文獻翻譯》電腦版v5.4.3.2文科工具
/ 13.71M
小學語文作業生成器免費版(自動生成語文題) v1.2 中文綠色版文科工具
/ 602K
PaperEasy論文修改助手(論文查重降重) v4.0 免費版文科工具
/ 1M
公文寫作神器綠色版(文科工具) v2.7.0.16PC 免費版文科工具
/ 9M